



من علی شاکر هستم؛ روزنامهنگار و پژوهشگر هوش مصنوعی که میخواهم در این سلسله یادداشتها در درجۀ نخست دربارۀ اصول کاربرد هوش مصنوعی در رسانه بیشتر بدانم و بخوانم و بعد آن را در اختیار شما بگذارم.
در یادداشت شمارۀ 5 «از قلم تا الگوریتم» به نقش هوش مصنوعی در مدیریت بحرانهای روابطعمومی با پیش گرفتن رویکرد «نمادین» پرداختیم. به طبع میدانیم در دنیای پیچیدۀ روابطعمومی، مدیریت بحران نیازمند ترکیبی از دانش، تجربه و واکنش سریع است. اما آیا میتوان این فرایند پیچیده را به الگوریتمها و قوانین منطقی از پیش طراحی شده سپرد؟
برای همین در یادداشت شمارۀ پنج تلاشها برای فرمالیزه کردن واکنش به بحران در روابطعمومی را بررسی کردیم و نشان دادیم چهطور با سیستمهای خبرۀ رایانهای میتوان برخی بحرانها را مدیریت کرد ولی همانطور که دیدیم، قصه پیچیدهتر از این حرفهاست که بتوان با منطق پیشینی و از قبل طراحی شده، ماشینها را هوشمند کرد.
برای همین تمامی آن تلاشها در حوزۀ رویکرد نمادین به سمت رویکردهای ارتباطگرا (یا پیوندگرا) حرکت کرد؛ چون ماشینها با این رویکرد آن طور که باید و شاید نمیتوانستند به تجربه و درک انسانی نزدیک شوند. در بخش ششم این یادداشت همچنان منبع اصلی ما برای تشریح اتفاقهای تاریخی و رویکردهای مختلف هوش مصنوعی، فصل هفتم کتاب «تاریخچۀ مختصر هوش» (2023) است و مثالها بر مبنای تجربه و رشتۀ نگارنده عرضه شدهاند. در این بخش توضیح میدهیم که رویکرد ارتباطگرا چیست و چرا عامل تمامی تحولاتی است که اکنون در عرصۀ هوشمندسازی ماشینها میبینیم.
پس همانطور که تا اینجا توضیح دادیم، با وجود خلاقانه بودن رویکردهای نمادین در حل مسائل به کمک ماشین، ما انسانها نمیتوانیم برای تمامی پدیدههای اطراف خود قواعدی منطقی تعیین کنیم. چون بسیاری از پدیدهها با منطق انسانی هماهنگ نیست. نمیتوانیم منطقِ پدیدههایی را که کامل نمیشناسیم، درک کنیم. البته که در جهان ما این پدیدههای ناشناخته کم نیست.
از این رو، بهتدریج دانشمندان دریافتند که میبایست از رویکرد نمادین دست کشید و آن را کامل کنار گذاشت و رویکردهای تازهای را برای آموزش ماشین در پیش گرفت.
هوش مصنوعی مبتنی بر ارتباطگرایی
دانشمندان ارتباطگرای هوش مصنوعی معتقدند که این فناوری از بایومیمیکری (یعنی الگوگیری از سیستمهای زیستی) بهویژه مطالعۀ مدلهای مغز انسان سرچشمه میگیرد. دستاورد شاخص این مکتب، مدل مغزی است که مککالاک فیزیولوژیست و پیتس ریاضیدان سال 1943 طراحی کردند که به مدل MP معروف است. این دو با استفاده از دستگاههای الکترونیک راههای جدیدی را گشودند برای تقلید از ساختار و عملکرد مغز انسان. این پژوهشها با مطالعۀ نورونها آغاز شد و سپس به مدلهای شبکۀ عصبی و مدلهای مغزی گسترش یافت و مسیر جدیدی برای توسعۀ هوش مصنوعی گشود.
پرسپترون
اولین نمونه از هوش مصنوعی مبتنی بر مغز، پرسپترون بود. این ماشین هوشمند را فرانک روزنبلات روانشناس در دهۀ 1950 اختراع کرد.[1] در این مدل از نحوۀ پردازش اطلاعات نورونهای مغز الهام گرفته شده بود، همانطور که در شکل 1 نشان داده شده است. یک نورون از سایر نورونها ورودی الکتریکی یا شیمیایی دریافت میکند. اگر مجموع تمام ورودیها به یک آستانه معین برسد، نورون [مغز] فعال میشود.
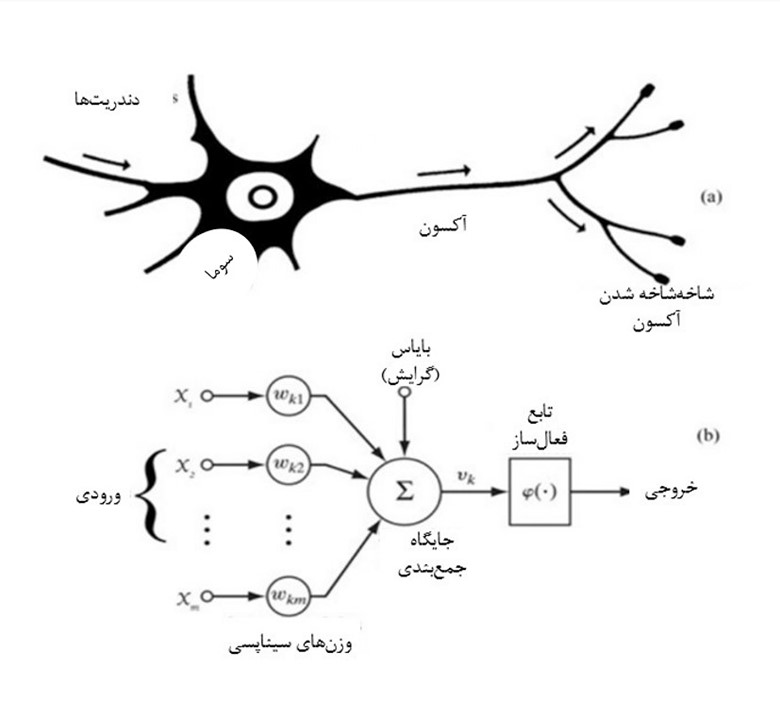
ساختار نورونی در مغز انسان شامل سه بخش اصلی است: دندریتها، سوما (بدنۀ سلولی) و آکسون. دندریتها شاخههایی هستند که پیامهای الکتروشیمیایی را از نورونهای دیگر دریافت میکنند. این پیامها به سمت سوما حرکت میکنند، که مرکز پردازش اصلی نورون است. در سوما، این پیامها تجمیع و پردازش میشوند. سپس، اگر پیام به اندازۀ کافی قوی باشد، از طریق آکسون به نورونهای دیگر منتقل میشود.
آکسون، بخشی طولانی از نورون است که پیامهای الکتریکی را به نقاط دیگر ارسال میکند. انتهای آکسون، انشعابهایی هست به نام شاخهشاخهشدن آکسون. این انشعابها به انتقال پیام به دیگر نورونها یا سلولهای هدف کمک میکنند. این ساختار، اساسیترین واحد سیستم عصبی است که امکان انتقال و پردازش اطلاعات را در مغز فراهم میکند.
این شکل عملکرد مغز در روزمرگیهای روزنامهنگارها هم به چشم میآید. برای مثال ما روزنامهنگارها هر روز با حجم زیادی از اطلاعات و دادهها مواجهایم؛ از پایگاههای خبری و پرتالهای سازمانی اخبار و گزارشهای متفاوتی به تحریریه میرسد. این دادهها را شبیه ورودیهای متعدد به سیستم عصبی (دندریتها) در نظر بگیرید. روزنامهنگار این دادهها را در ذهنش (شبیه سوما) پردازش و تجزیهوتحلیل میکند. در نهایت، وقتی دادهها به حدی از اهمیت و صحت میرسند که به نوعی آستانۀ فکری دست مییابند، او تصمیم میگیرد آنها را به شکل یک خبر یا گزارش منتشر کند (مانند آکسون که پیام نهایی را به دیگران منتقل میکند).
در مدلهای شبکۀ عصبی مصنوعی، که از ساختار نورونهای زیستی الهام گرفته شدهاند، ورودیها (Inputs) بهعنوان دادههای اولیه به سیستم وارد میشوند. این ورودیها میتوانند از لایههای پیشین شبکه یا از دادههای خام گرفته شوند و به نورون موردنظر ارسال شوند. هر ورودی متأثر از وزنهای سیناپسی (Synaptic Weights) است. این وزنها پارامترهای قابل تنظیمیاند که در طول فرایند آموزش مدل بهینه میشوند تا تأثیر هر ورودی در خروجی نهایی را مشخص کنند. در واقع، وزنهای سیناپسی تعیین میکنند که کدام ورودیها اهمیت بیشتری دارند و در پیشبینی نهایی نقش بیشتری ایفا میکنند.
در ادامه، بایاس (Bias) یا گرایش که یک مقدار ثابت است، به مجموع ورودیها اضافه میشود. نورونها به کمک بایاس میتوانند انعطافپذیری بیشتری داشته باشند و تابع فعالسازی را به نحوی جابهجا کند که بتواند بهتر دادهها را مدل کند. در واقع، نورنها با این پارامترها میتوانند در شرایط پیچیده، تصمیمهای دقیقتری بگیرند.

مجموعهای از ورودیها که در وزنهای سیناپسی خود ضرب شدهاند، به همراه بایاس، در جایگاه جمعبندی (Summing Junction) گرد هم میآیند. نتیجۀ این عملیات بهعنوان ورودی تابع فعالسازی (Activation Function) در نظر گرفته میشود. تابع فعالسازی وظیفه دارد که تصمیم بگیرد آیا نورون فعال شود یا خیر. این توابع معمولاً غیرخطی هستند و شامل توابعی مانند ReLU، سیگموید، و هایپربولیک میشوند که باعث میشود شبکۀ عصبی بتواند روابط غیرخطی میان دادهها را یاد بگیرد و به پیشبینیهای دقیقتری برسد.
خروجی نهایی پس از عبور از تابع فعالسازی به دست میآید و میتواند بهعنوان ورودی به نورونهای دیگر در لایههای بعدی یا بهعنوان نتیجۀ نهایی مدل مورد استفاده قرار گیرد. این ساختار ساده ولی کارآمد از نحوۀ عملکرد نورونهای مصنوعی، به شبکههای عصبی این امکان را میدهد تا در حوزههای مختلفی مانند یادگیری عمیق (Deep Learning) و تحلیل دادههای پیچیده، عملکرد بالایی از خود نشان دهند.
در کل، تنظیم وزنها و بایاسها در طول فرایند آموزش، کلید عملکرد بهینۀ شبکۀ عصبی است. این پارامترها باتوجهبه دادههای ورودی و خروجیهای هدف تغییر میکنند تا شبکه بتواند به تدریج یاد بگیرد و به نتایج بهتری دست یابد. بههمیندلیل، نورونهای مصنوعی میتوانند به گونهای طراحی شوند که فرایندهای پیچیدۀ مغزی را شبیهسازی کنند و در کاربردهای متنوعی از جمله تشخیص الگو، طبقهبندی دادهها و پیشبینی آینده استفاده شوند.
هنگام محاسبۀ مجموع ورودیهای خود، نورون به ورودیهایی که از اتصالات قویتر میآیند وزن بیشتری میدهد. تنظیم قدرت اتصالات بین نورونها یکی از اجزای کلیدی نحوۀ یادگیری در مغز است.
مشابه یک نورون، یک پرسپترون مجموع وزنی ورودیهای خود را محاسبه میکند که اگر این مجموع به یک آستانۀ خاص برسد، خروجی آن 1 خواهد بود.
برای اینکه مفهوم پرسپترون و رویکرد شبکههای عصبی مصنوعی در دنیای روزنامهنگاری بهتر درک شود، میتوانیم مثالی مرتبط با پردازش و تحلیل دادههای خبری ارائه دهیم.
فرض کنید در یک روزنامه، وظیفۀ تحلیل هزاران مقالۀ خبری در مورد یک رویداد خاص به شما سپرده شده است. به جای اینکه خودتان بهصورت دستی هر مقاله را بخوانید و تحلیل کنید، میتوانید از یک مدل شبکۀ عصبی مصنوعی مانند پرسپترون استفاده کنید. این مدل میتواند تمام مقالات ورودی را دریافت کند و هر کدام از آنها را بر اساس وزنهای مختلفی که به کلمات یا مفاهیم کلیدی درون آنها داده شده، تحلیل کند. برای مثال، اگر یک مقاله شامل کلماتی باشد که بیانگر «تنش»، «اعتراض» یا «بحران» است، این کلمات وزن بیشتری خواهند داشت، چون به موضوع رویداد مرتبط هستند.
مدل پرسپترون مجموع این وزنها را محاسبه میکند و اگر این مجموع به یک آستانۀ خاص برسد، مثلاً تصمیم گرفته میشود که این مقاله نشاندهندۀ وضعیت بحرانی است و نیاز به انتشار سریع دارد. در واقع، خروجی پرسپترون میتواند تصمیمگیری کند که آیا یک مقاله باید در اولویت قرار گیرد یا خیر، همانطور که نورونها در مغز برای تشخیص اهمیت یک پیام الکتریکی عمل میکنند.
در این مثال، «ورودیها» همان مقالات خبریاند که هر کدام به لحاظ اهمیت موضوع وزنهای مختلفی دارند (مثلاً وزن بیشتری برای کلماتی که مربوط به بحرانها و مسائل حساس هستند). «وزنهای سیناپسی» نشاندهندۀ میزان تأثیر هر کلمه یا مفهوم در تحلیل نهایی است.
«بایاس» کمک میکند که حتی اگر برخی از ورودیها ضعیف باشند، سیستم بتواند انعطافپذیری خود را حفظ کند و تصمیمات بهتری بگیرد و این «تابع فعالسازی» است که در نهایت تعیین میکند آیا مقالهای باید بهعنوان بحرانی شناخته شود یا خیر.
پس همانطور که نورونها اطلاعات را پردازش میکنند، سیستمهای هوش مصنوعی نیز میتوانند برای تحلیل دادههای خبری و روزنامهنگاری به کار آیند و این کار با سرعت و دقت بسیار بیشتری نسبت به روشهای سنتی انجام میشود. این به روزنامهنگاران کمک میکند تا در مواجهه با حجم زیادی از دادهها، سریعتر و دقیقتر تصمیم بگیرند.
چگونه میتوان وزنها و آستانهها را در پرسپترون تعیین کرد؟
برخلاف هوش مصنوعی نمادین، که دارای قوانین صریحی است که برنامهنویس آن را تعیین میکند، پرسپترون این مقادیر را بهصورت خودکار با مثالهای آموزشی یاد میگیرد. در فرایند آموزش، اگر نتیجه درست باشد، پاداش میگیرد؛ در غیر این صورت، تنبیه میشود.
اگر با اضافه کردن لایههای بیشتری از پرسپترون، این مدل گسترش یابد، میتوان مشکلات گستردهتری را با این رویکرد حل کرد. این ساختار نوین، همان شبکۀ عصبی چندلایه است که اساس بسیاری از انواع هوش مصنوعی مدرن را تشکیل میدهد.
بااینحال، در دهل 1950 و 1960، آموزش شبکههای عصبی کار دشواری بود؛ چون الگوریتمهای عمومی برای یادگیری وزنها و آستانهها وجود نداشت. متأسفانه، فرانک روزنبلات در سال 1971 در سن 43 سالگی بر اثر حادثۀ قایقرانی درگذشت. به دلیل محدودیتهای مدلهای نظری، پروتوتایپهای زیستی و شرایط فنی آن زمان، پژوهشها دربارۀ مدلهای مغزی در اواخر دهۀ 1970 و اوایل دهۀ 1980 به محاق رفت. بدون حامیان برجسته و حمایتهای دولتی کافی، پژوهش در زمینۀ شبکههای عصبی و سایر هوشهای مصنوعی مبتنی بر ارتباطگرایی تا حد زیادی متوقف شد. بهویژه به دلیل انتقادات شدید ماروین مینسکی از پرسپترون، مکتب ارتباطگرایی (یا شبکۀ عصبی) تقریباً به مدت یک دهه در رکود بود.
یادگیری ماشینی
اگرچه تأمین مالی برای پژوهشهای مرتبط با رویکرد ارتباطگرایی به شدت کم شد، اما برخی از پژوهشگران این حوزه در دهههای 1970 و 1980 به کار خود ادامه دادند. ارتباطگرایی تنها پس از انتشار دو مقالۀ مهم توسط پروفسور جان جی. هاپفیلد [برندۀ نوبل فیزیک امسال به همراه جفری هینتون که به او میگویند پدرخواندۀ هوش مصنوعی] در سالهای 1982 و 1984، که پیشنهاد شبیهسازی شبکههای عصبی در سختافزار را مطرح کرد [2، 3]، دوباره احیا شد.
در سال 1986، راملهارت و همکارانش الگوریتم بازگشت به عقب یا پسانتشار (BP) را در شبکههای چندلایه پیشنهاد کردند. از آن زمان، ارتباطگرایی شتاب گرفت، از مدل به الگوریتم، از تحلیل نظری به پیادهسازی مهندسی، و پایهای را برای ورود شبکههای عصبی به بازار فراهم کرد.
یادگیری ماشینی از سال 2010 بهعنوان یک تغییر پارادایم کامل نسبت به سیستمهای خبره بسیار محبوب شد. یادگیری ماشینی نیازی به کدنویسی قوانین سیستمهای خبره ندارد، بلکه به رایانهها اجازه میدهد قوانین را بر اساس حجم وسیعی از دادهها کشف کنند.
یادگیری ماشینی زیرمجموعهای از رویکرد ارتباطگرایی به هوش مصنوعی است که مغز را شبیهسازی میکند. برخلاف هوش مصنوعی نمادین که تلاش میکند مفاهیم تفکر سطح بالا را تقلید کند، هوش مصنوعی ارتباطگرا شبکههای تطبیقی ایجاد میکند که میتوانند «یاد بگیرند» و الگوهایی را از حجم زیادی از دادهها بشناسد. با داشتن الگوریتمهای پیچیدهتر و کلاندادههای بیشتر، طرفداران ارتباطگرایی بر این باورند که میتوان به سطوح بالاتری از عملکرد هوش مصنوعی رسید که میتواند معادل ذهن واقعی انسان باشد.
در یادداشت بعدی (هفتم) از قلم تا الگوریتم، سعی میکنیم که به لحاظ فنی و ریاضی توضیح دهیم که داخل این ماشینهای هوشمند چه اتفاقی میافتد که بر اساس فرمولهای آمار پیشرفته و ریاضی حتی میتوانند پیشبینی انجام دهند.
- Rosenblatt, The Perceptron: A Perceiving and Recognizing Automaton, Report 85–60-1(Cornell Aeronautical Laboratory, Buffalo, New York, 1957)
- هاپفیلد، ج. ج. (۱۹۸۲). شبکههای عصبی و سیستمهای فیزیکی با قابلیتهای محاسباتی جمعی نوظهور. مجله آکادمی ملی علوم ایالات متحده آمریکا, ۷۹(۸)، ۲۵۵۴-۲۵۵۸.
- جان جی، اچ. (۱۹۸۴). نورونهایی با پاسخ تدریجی دارای خواص محاسباتی جمعی مشابه نورونهای دو حالتی هستند. مجله آکادمی ملی علوم ایالات متحده آمریکا, ۸۱(۱۰)، ۳۰۸۸-۳۰۹۲.





